Recently we’re using ElasticSearch as a data backend of our recommendation API, to serve both offline and online computed data to users. Thanks to ElasticSearch’s rich and out-of-the-box functionality, it doesn’t take much trouble to setup the cluster. However, we still encounter some misuse and unwise configurations. So here’s a list of ElasticSearch performance tips that we learned from practice.
Tip 1 Set Num-of-shards to Num-of-nodes
Shard is the foundation of ElasticSearch’s distribution capability. Every index is splitted into several shards (default 5) and are distributed across cluster nodes. But this capability does not come free. Since data being queried reside in all shards (this behaviour can be changed by routing), ElasticSearch has to run this query on every shard, fetch the result, and merge them, like a map-reduce process. So if there’re too many shards, more than the number of cluter nodes, the query will be executed more than once on the same node, and it’ll also impact the merge phase. On the other hand, too few shards will also reduce the performance, for not all nodes are being utilized.
Shards have two roles, primary shard and replica shard. Replica shard serves as a backup to the primary shard. When primary goes down, the replica takes its job. It also helps improving the search and get performance, for these requests can be executed on either primary or replica shard.
Shards can be visualized by elasticsearch-head plugin:
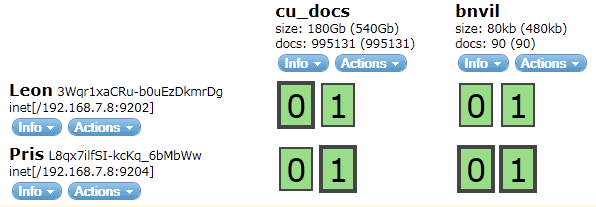
The cu_docs index has two shards 0 and 1, with number_of_replicas set to 1. Primary shard 0 (bold bordered) resides in server Leon, and its replica in Pris. They are green becuase all primary shards have enough repicas sitting in different servers, so the cluster is healthy.
Since number_of_shards of an index cannot be changed after creation (while number_of_replicas can), one should choose this config wisely. Here are some suggestions:
- How many nodes do you have, now and future? If you’re sure you’ll only have 3 nodes, set number of shards to 2 and replicas to 1, so there’ll be 4 shards across 3 nodes. If you’ll add some servers in the future, you can set number of shards to 3, so when the cluster grows to 5 nodes, there’ll be 6 distributed shards.
- How big is your index? If it’s small, one shard with one replica will due.
- How is the read and write frequency, respectively? If it’s search heavy, setup more relicas.
Tip 2 Tuning Memory Usage
ElasticSearch and its backend Lucene are both Java application. There’re various memory tuning settings related to heap and native memory.
Set Max Heap Size to Half of Total Memory
Generally speaking, more heap memory leads to better performance. But in ElasticSearch’s case, Lucene also requires a lot of native memory (or off-heap memory), to store index segments and provide fast search performance. But it does not load the files by itself. Instead, it relies on the operating system to cache the segement files in memory.
Say we have 16G memory and set -Xmx to 8G, it doesn’t mean the remaining 8G is wasted. Except for the memory OS preserves for itself, it will cache the frequently accessed disk files in memory automatically, which results in a huge performance gain.
Do not set heap size over 32G though, even you have more than 64G memory. The reason is described in this link.
Also, you should probably set -Xms to 8G as well, to avoid the overhead of heap memory growth.
Disable Swapping
Swapping is a way to move unused program code and data to disk so as to provide more space for running applications and file caching. It also provides a buffer for the system to recover from memory exhaustion. But for critical application like ElasticSearch, being swapped is definitely a performance killer.
There’re several ways to disable swapping, and our choice is setting bootstrap.mlockall to true. This tells ElasticSearch to lock its memory space in RAM so that OS will not swap it out. One can confirm this setting via http://localhost:9200/_nodes/process?pretty.
If ElasticSearch is not started as root (and it probably shouldn’t), this setting may not take effect. For Ubuntu server, one needs to add <user> hard memlock unlimited to /etc/security/limits.conf, and run ulimit -l unlimited before starting ElasticSearch process.
Increase mmap Counts
ElasticSearch uses memory mapped files, and the default mmap counts is low. Add vm.max_map_count=262144 to /etc/sysctl.conf, run sysctl -p /etc/sysctl.conf as root, and then restart ElasticSearch.
Tip 3 Setup a Cluster with Unicast
ElasticSearch has two options to form a cluster, multicast and unicast. The former is suitable when you have a large group of servers and a well configured network. But we found unicast more concise and less error-prone.
Here’s an example of using unicast:
1 | node.name: "NODE-1" |
The discovery.zen.minimum_master_nodes setting is a way to prevent split-brain symptom, i.e. more than one node thinks itself the master of the cluster. And for this setting to work, you should have an odd number of nodes, and set this config to ceil(num_of_nodes / 2). In the above cluster, you can lose at most one node. It’s much like a quorum in Zookeeper.
Tip 4 Disable Unnecessary Features
ElasticSearch is a full-featured search engine, but you should always tailor it to your own needs. Here’s a brief list:
- Use corrent index type. There’re
index,not_analyzed, andno. If you don’t need to search the field, set it tono; if you only search for full match, usenot_analyzed. - For search-only fields, set
storeto false. - Disable
_allfield, if you always know which field to search. - Disable
_sourcefields, if documents are big and you don’t need the update capability. - If you have a document key, set this field in
_id-path, instead of index the field twice. - Set
index.refresh_intervalto a larger number (default 1s), if you don’t need near-realtime search. It’s also an important option in bulk-load operation described below.
Tip 5 Use Bulk Operations
- Bulk Read
- Use Multi Get to retrieve multiple documents by a list of ids.
- Use Scroll to search a large number of documents.
- Use MultiSearch api to run search requests in parallel.
- Bulk Write
- Use Bulk API to index, update, delete multiple documents.
- Alter index aliases simultaneously.
- Bulk Load: when initially building a large index, do the following,
- Set
number_of_relicasto 0, so no relicas will be created; - Set
index.refresh_intervalto -1, disabling nrt search; - Bulk build the documents;
- Call
optimizeon the index, so newly built docs are available for search; - Reset replicas and refresh interval, let ES cluster recover to green.
- Set
Miscellaneous
- File descriptors: system default is too small for ES, set it to 64K will be OK. If
ulimit -n 64000does not work, you need to add<user> hard nofile 64000to/etc/security/limits.conf, just like thememlocksetting mentioned above. - When using ES client library, it will create a lot of worker threads according to the number of processors. Sometimes it’s not necessary. This behaviour can be changed by setting
processorsto a lower value like 2:
1 | val settings = ImmutableSettings.settingsBuilder() |
References
- https://www.elastic.co/guide/en/elasticsearch/guide/current/index.html
- https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
- http://cpratt.co/how-many-shards-should-elasticsearch-indexes-have/
- https://www.elastic.co/blog/performance-considerations-elasticsearch-indexing
- https://www.loggly.com/blog/nine-tips-configuring-elasticsearch-for-high-performance/