Apache Flink is another popular big data processing framework, which differs from Apache Spark in that Flink uses stream processing to mimic batch processing and provides sub-second latency along with exactly-once semantics. One of its use cases is to build a real-time data pipeline, move and transform data between different stores. This article will show you how to build such an application, and explain how Flink guarantees its correctness.
Demo ETL Application
Let us build a project that extracts data from Kafka and loads them into HDFS. The result files should be stored in bucketed directories according to event time. Source messages are encoded in JSON, and the event time is stored as timestamp. Samples are:
1 | {"timestamp":1545184226.432,"event":"page_view","uuid":"ac0e50bf-944c-4e2f-bbf5-a34b22718e0c"} |
The result directory structure should be:
1 | /user/flink/event_log/dt=20181219/part-0-1 |
Create Project
Flink application requires Java 8, and we can create a project from Maven template.
1 | mvn archetype:generate \ |
Import it into your favorite IDE, and we can see a class named StreamingJob. We will start from there.
Kafka Consumer Source
Flink provides native support for consuming messages from Kafka. Choose the right version and add to dependencies:
1 | <dependency> |
We need some Kafka server to bootstrap this source. For testing, one can follow the Kafka official document to setup a local broker. Create the source and pass the host and topic name.
1 | Properties props = new Properties(); |
Flink will read data from a local Kafka broker, with topic flink_test, and transform it into simple strings, indicated by SimpleStringSchema. There are other built-in deserialization schema like JSON and Avro, or you can create a custom one.
Streaming File Sink
StreamingFileSink is replacing the previous BucketingSink to store data into HDFS in different directories. The key concept here is bucket assigner, which defaults to DateTimeBucketAssigner, that divides messages into timed buckets according to processing time, i.e. the time when messages arrive the operator. But what we want is to divide messages by event time, so we have to write one on our own.
1 | public class EventTimeBucketAssigner implements BucketAssigner<String, String> { |
We create a bucket assigner that ingests a string, decodes with Jackson, extracts the timestamp, and returns the bucket name of this message. Then the sink will know where to put them. Full code can be found on GitHub (link).
1 | StreamingFileSink<String> sink = StreamingFileSink |
There is also a forBulkFormat, if you prefer storing data in a more compact way like Parquet.
A note on StreamingFileSink though, it only works with Hadoop 2.7 and above, because it requires the file system supporting truncate, which helps recovering the writing process from the last checkpoint.
Enable Checkpointing
So far, the application can be put into work by invoking env.execute(), but it only guarantees at-least-once semantics. To achieve exactly-once, we simply turn on Flink’s checkpointing:
1 | env.enableCheckpointing(60_000); |
Checkpoint is Flink’s solution to fault tolerance, which we will cover later. Here we switch the state backend from default MemoryStateBackend to FsStateBackend, that stores state into filesystem like HDFS, instead of in memory, to help surviving job manager failure. Flink also recommends using RocksDBStateBackend, when job state is very large and requires incremental checkpointing.
Submit and Manage Jobs
Flink application can be directly run in IDE, or you can setup a local standalone cluster and submit jobs with Flink CLI:
1 | bin/flink run -c flink.kafka.KafkaLoader target/sandbox-flink-0.0.1-SNAPSHOT.jar |
We can check out the job information in Flink dashboard:
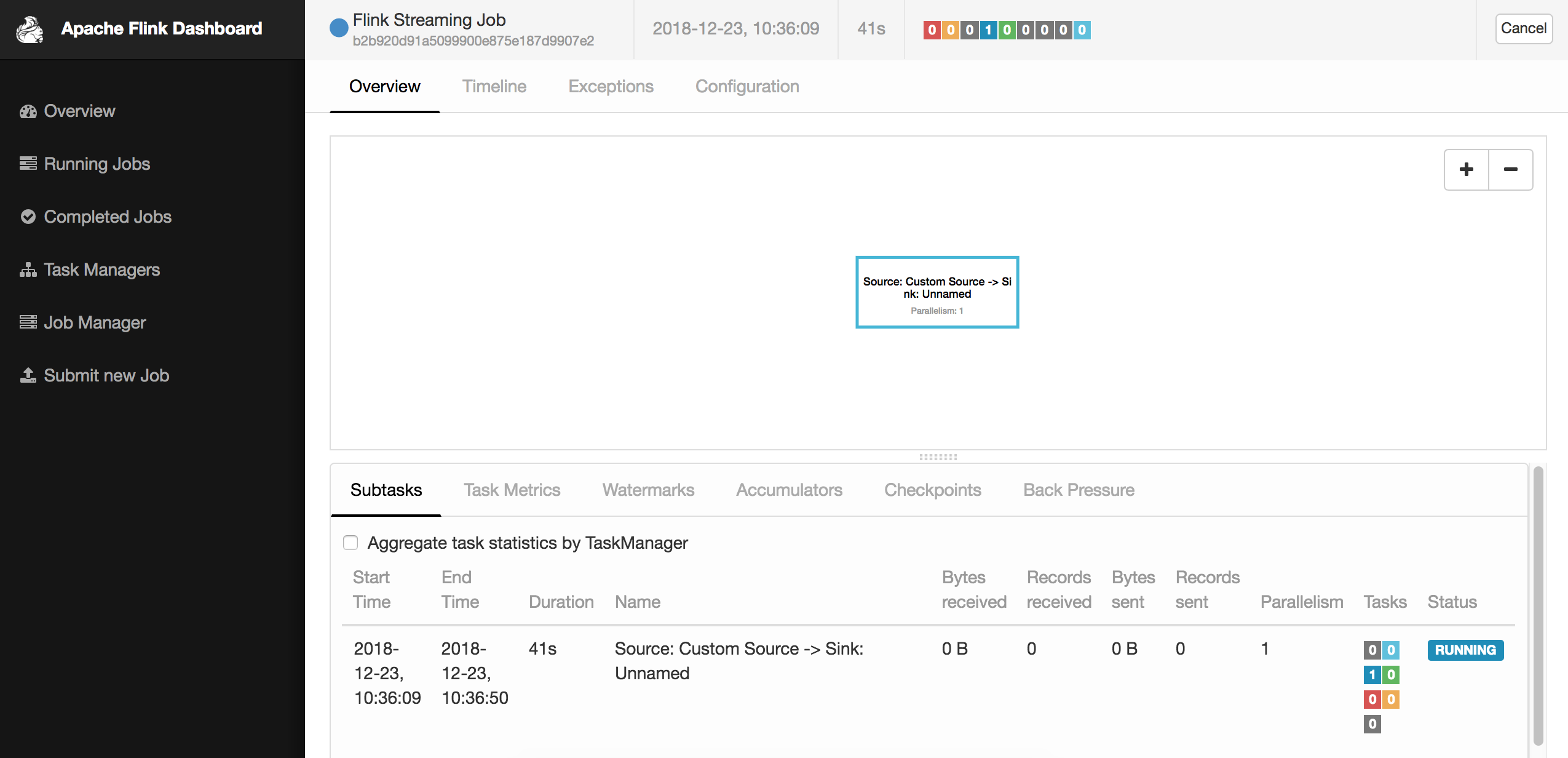
Cancel and Resume Job with Savepoint
To cancel or restart the job, say we want to upgrade the code logic, we need to create a savepoint. A savepoint is like a checkpoint, storing state of the running tasks. But savepoint is usually manually created, for planned backup or upgrade, while checkpoint is managed by Flink to provide fault tolerance. The cancel sub-command accepts -s option to write savepoint into some directory.
1 | $ bin/flink cancel -s /tmp/flink/savepoints 1253cc85e5c702dbe963dd7d8d279038 |
For our ETL application, savepoint will include current Kafka offsets, in-progress output file names, etc. To resume from a savepoint, pass -s to run sub-command. The application will start from the savepoint, i.e. consume messages right after the saved offsets, without losing or duplicating data.
1 | flink run -s /tmp/flink/savepoints/savepoint-1253cc-0df030f4f2ee -c flink.kafka.KafkaLoader target/sandbox-flink-0.0.1-SNAPSHOT.jar |
YARN Support
Running Flink jobs on YARN also uses flink run. Replace the file paths with HDFS prefix, re-package and run the following command:
1 | $ export HADOOP_CONF_DIR=/path/to/hadoop/conf |
Flink dashboard will run in YARN application master. The returned application ID can be used to manage the jobs through Flink CLI:
1 | bin/flink cancel -s hdfs://localhost:9000/tmp/flink/savepoints -yid application_1545534487726_0001 84de00a5e193f26c937f72a9dc97f386 |
How Flink Guarantees Exactly-once Semantics
Flink streaming application can be divided into three parts, source, process, and sink. Different sources and sinks, or connectors, give different guarantees, and the Flink stream processing gives either at-least-once or exactly-once semantics, based on whether checkpointing is enabled.
Stream Processing with Checkpointing
Flink’s checkpointing mechanism is based on Chandy-Lamport algorithm. It periodically inserts light-weight barriers into data stream, dividing the stream into sets of records. After an operator has processed all records in the current set, a checkpoint is made and sent to the coordinator, i.e. job manager. Then the operator will send this barrier to its down-streams. When all sinks finish checkpointing, this checkpoint is marked as completed, which means all data before the checkpoint has been properly processed, all operator states are saved, and the application can recover from this checkpoint when encountering failures.
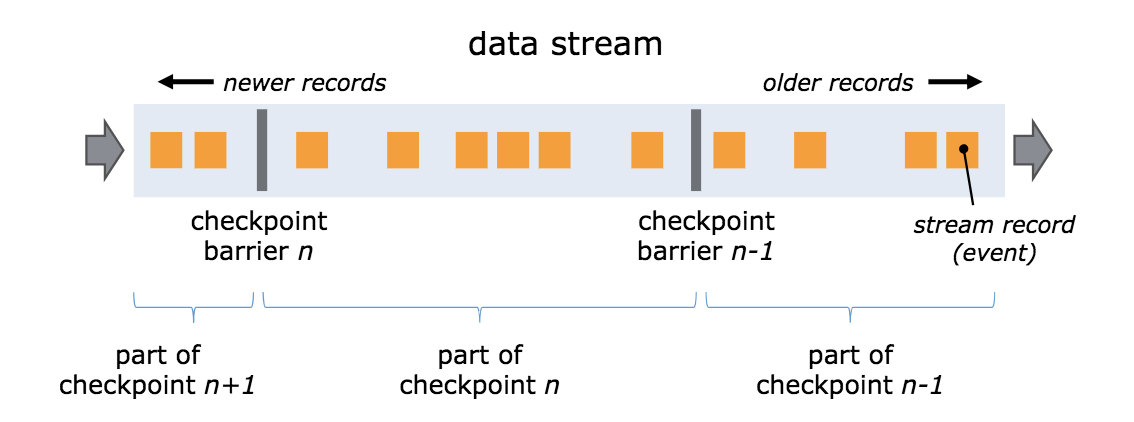
For operators with multiple up-streams, a technique called stream aligning is applied. If one of the up-streams is delayed, the operator will stop processing data from other up-streams, until the slow one catches up. This guarantees exactly-once semantics of the operator state, but will certainly introduce some latency. Apart from this EXACTLY_ONCE mode of checkpointing, Flink also provides AT_LEAST_ONCE mode, to minimize the delay. One can refer to document for further details.
Rewindable Data Source
When recovering from the last checkpoint, Flink needs to re-fetch some messages, and data source like Kafka supports consuming messages from given offsets. In detail, FlinkKafkaConsumer implements the CheckpointedFunction and stores topic name, partition ID, and offsets in operator state.
1 | abstract class FlinkKafkaConsumerBase implements CheckpointedFunction { |
When resuming a job from a savepoint, you can find the following lines in task manager logs, indicating that the source will consume from the offsets that are restored from checkpoint.
1 | 2018-12-23 10:56:47,380 INFO FlinkKafkaConsumerBase |
Recover In-progress Output Files
As the application runs, StreamingFileSink will first write to a temporary file, prefixed with dot and suffixed with in-progress. The in-progress files are renamed to normal files according to some RollingPolicy, which defaults to both time-based (60 seconds) and size-based (128 MB). When task failure happens, or job is canceled, the in-progress files are simply closed. During recovery, the sink can retrieve in-progress file names from checkpointed state, truncate the files to a specific length, so that they do not contain any data after the checkpoint, and then the stream processing can resume.
Take Hadoop file system for instance, the recovering process happens in HadoopRecoverableFsDataOutputStream class constructor. It is invoked with a HadoopFsRecoverable object that contains the temporary file name, target name, and offset. This object is a member of BucketState, which is stored in operator state.
1 | HadoopRecoverableFsDataOutputStream(FileSystem fs, HadoopFsRecoverable recoverable) { |
Conclusions
Apache Flink builds upon stream processing, state management is considered from day one, and it integrates well with Hadoop ecosystem. All of these make it a very competitive product in big data field. It is under active development, and gradually gains more features like table API, stream SQL, machine learning, etc. Big companies like Alibaba are also using and contributing to this project. It supports a wide range of use-cases, and is definitely worth a try.