Recently we’re using ElasticSearch as a data backend of our recommendation API, to serve both offline and online computed data to users. Thanks to ElasticSearch’s rich and out-of-the-box functionality, it doesn’t take much trouble to setup the cluster. However, we still encounter some misuse and unwise configurations. So here’s a list of ElasticSearch performance tips that we learned from practice.
Tip 1 Set Num-of-shards to Num-of-nodes
Shard is the foundation of ElasticSearch’s distribution capability. Every index is splitted into several shards (default 5) and are distributed across cluster nodes. But this capability does not come free. Since data being queried reside in all shards (this behaviour can be changed by routing), ElasticSearch has to run this query on every shard, fetch the result, and merge them, like a map-reduce process. So if there’re too many shards, more than the number of cluter nodes, the query will be executed more than once on the same node, and it’ll also impact the merge phase. On the other hand, too few shards will also reduce the performance, for not all nodes are being utilized.
Shards have two roles, primary shard and replica shard. Replica shard serves as a backup to the primary shard. When primary goes down, the replica takes its job. It also helps improving the search and get performance, for these requests can be executed on either primary or replica shard.
Shards can be visualized by elasticsearch-head plugin:
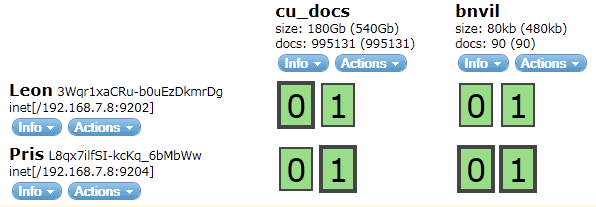
The cu_docs index has two shards 0 and 1, with number_of_replicas set to 1. Primary shard 0 (bold bordered) resides in server Leon, and its replica in Pris. They are green becuase all primary shards have enough repicas sitting in different servers, so the cluster is healthy.
Since number_of_shards of an index cannot be changed after creation (while number_of_replicas can), one should choose this config wisely. Here are some suggestions:
- How many nodes do you have, now and future? If you’re sure you’ll only have 3 nodes, set number of shards to 2 and replicas to 1, so there’ll be 4 shards across 3 nodes. If you’ll add some servers in the future, you can set number of shards to 3, so when the cluster grows to 5 nodes, there’ll be 6 distributed shards.
- How big is your index? If it’s small, one shard with one replica will due.
- How is the read and write frequency, respectively? If it’s search heavy, setup more relicas.
Read More
