Apache Hive introduced transactions since version 0.13 to fully support ACID semantics on Hive table, including INSERT/UPDATE/DELETE/MERGE statements, streaming data ingestion, etc. In Hive 3.0, this feature is further improved by optimizing the underlying data file structure, reducing constraints on table scheme, and supporting predicate push down and vectorized query. Examples and setup can be found on Hive wiki and other tutorials, while this article will focus on how transactional table is saved on HDFS, and take a closer look at the read-write process.
File Structure
Insert Data
1 | CREATE TABLE employee (id int, name string, salary int) |
An INSERT statement is executed in a single transaction. It will create a delta directory containing information about this transaction and its data.
1 | /user/hive/warehouse/employee/delta_0000001_0000001_0000 |
The schema of this folder’s name is delta_minWID_maxWID_stmtID, i.e. “delta” prefix, transactional writes’ range (minimum and maximum write ID), and statement ID. In detail:
- All INSERT statements will create a
deltadirectory. UPDATE statement will also createdeltadirectory right after adeletedirectory.deletedirectory is prefixed with “delete_delta”. - Hive will assign a globally unique ID for every transaction, both read and write. For transactional writes like INSERT and DELETE, it will also assign a table-wise unique ID, a.k.a. a write ID. The write ID range will be encoded in the
deltaanddeletedirectory names. - Statement ID is used when multiple writes into the same table happen in one transaction.
For its content, _orc_acid_version always contains “2”, indicating this directory is in ACID version 2 format. Compared with previous version, the main difference is that UPDATE now uses split-update technique to support predicate push down and other features (HIVE-14035). bucket_00000 is the inserted records. Since this table is not bucketed, there is only one file, and it is in ORC format. We can take a look at its content with orc-tools:
1 | $ orc-tools data bucket_00000 |
The file content is displayed in JSON, row-wise. We can see the actual data is in row, while other keys work for transaction mechanism:
operation0 means INSERT, 1 UPDATE, and 2 DELETE. UPDATE will not appear because of the split-update technique mentioned above.originalTransactionis the previous write ID. For INSERT, it is the same ascurrentTransaction. For DELETE, it is the write ID when this record is first created.bucketis a 32-bit integer defined byBucketCodecclass. Their meanings are:- bit 1-3: bucket codec version, currently
001. - bit 4: reserved for future.
- bit 5-16: the bucket ID, 0-based. This ID is determined by CLUSTERED BY columns and number of buckets. It matches the
bucket_Nprefixed files. - bit 17-20: reserved for future.
- bit 21-32: statement ID.
- For instance, the binary form of
536936448is00100000000000010000000000000000, showing it is a version 1 codec, and bucket ID is 1.
- bit 1-3: bucket codec version, currently
rowIdis the auto-generated unique ID within the transaction and bucket.currentTransactionis the current write ID.rowcontains the actual data. For DELETE,rowwill be null.
We can note that the data rows are ordered by (originalTransaction, bucket, rowId), which is essential for the reading process.
These information can also be viewed by the row__id virtual column:
1 | SELECT row__id, id, name, salary FROM employee; |
Output:
1 | {"writeid":1,"bucketid":536870912,"rowid":0} 1 Jerry 5000 |
Streaming Data Ingest V2
Hive 3.0 also upgrades the former Streaming API. Now users or third-party tools like Flume can use the ACID feature writing data continuously into Hive table. These operations will also create delta directories. But mutation is no longer supported.
1 | StreamingConnection connection = HiveStreamingConnection.newBuilder().connect(); |
Update Data
1 | UPDATE employee SET salary = 7000 WHERE id = 2; |
This statement will first run a query to find out the row__id of the updating records, and then create a delete directory a long with a delta directory:
1 | /user/hive/warehouse/employee/delta_0000001_0000001_0000/bucket_00000 |
Content of delete_delta_0000002_0000002_0000/bucket_00000:
1 | {"operation":2,"originalTransaction":1,"bucket":536870912,"rowId":1,"currentTransaction":2,"row":null} |
Content of delta_0000002_0000002_0000/bucket_00000:
1 | {"operation":0,"originalTransaction":2,"bucket":536870912,"rowId":0,"currentTransaction":2,"row":{"id":2,"name":"Tom","salary":7000}} |
DELETE statement works similarly to UPDATE, i.e. find the record but generate only delete directory.
Merge Statement
MERGE is like MySQL’s INSERT ON UPDATE. It can update target table with a source table. For instance:
1 | CREATE TABLE employee_update (id int, name string, salary int); |
This statement will update the salary of Tom, and insert a new row of Mary. WHENs are considered different statements. The INSERT clause generates delta_0000002_0000002_0000, containing the row of Mary, while UPDATE generates delete_delta_0000002_0000002_0001 and delta_0000002_0000002_0001, deleting and inserting the row of Tom.
1 | /user/hive/warehouse/employee/delta_0000001_0000001_0000 |
Compaction
As time goes, there will be more and more delta and delete directories in the table, which will affect the read performance, since reading is a process of merging the results of valid transactions. Small files are neither friendly to file systems like HDFS. So Hive uses two kinds of compactors, namely minor and major, to merge these directories while preserving the transaction information.
Minor compaction will merge multiple delta and delete files into one delta and delete file, respectively. The transaction ID will be preserved in folder name as write ID range, as mentioned above, while omitting the statement ID. Compactions will be automatically initiated in Hive metastore process based on some configured thresholds. We can also trigger it manually with the following SQL:
1 | ALTER TABLE employee COMPACT 'minor'; |
Take the result of MERGE statement for an instance. After minor compaction, the folder structure will become:
1 | /user/hive/warehouse/employee/delete_delta_0000001_0000002 |
In delta_0000001_0000002/bucket_00000, rows are simply ordered and concatenated, i.e. two rows of Tom will be both included. Minor compact does not delete any data.
Major compaction, on the other hand, will merge and write the current table into a single directory, with the name base_N, where N is the latest write ID. Deleted data will be removed in major compaction. row_id remains untouched.
1 | /user/hive/warehouse/employee/base_0000002 |
Note that after minor or major compaction, the original files will not be deleted immediately. Deletion is carried out by a cleaner thread, so there will be multiple files containing the same transaction data simultaneously. Take this into account when understanding the reading process.
Reading Process
Now we see three kinds of files in an ACID table, base, delta, and delete. Each contains data rows that can be identified by row__id and sorted by it, too. Reading data from an ACID table is a process of merging these files, and reflecting the result of the last transaction. This process is written in OrcInputFormat and OrcRawRecordMerger class, and it is basically a merge-sort algorithm.
Take the following files for an instance. This structure can be generated by: insert three rows, do a major compaction, then update two rows. 1-0-0-1 is short for originalTransaction - bucketId (not encoded) - rowId - currentTransaction.
1 | +----------+ +----------+ +----------+ |
Merging process:
- Sort rows from all files by (
originalTransaction,bucketId,rowId) ascendingly, (currentTransaction) descendingly. i.e.1-0-0-11-0-1-21-0-1-1- …
2-0-1-2
- Fetch the first record.
- If the
row__idis the same as previous, skip. - If the operation is DELETE, skip.
- As a result, for
1-0-1-2and1-0-1-1, this row will be skipped.
- As a result, for
- Otherwise, emit the row.
- Repeat.
The merging is done in a streaming way. Hive will open all the files, read the first record, and construct a ReaderKey class, storing originalTransaction, bucketId, rowId, and currentTransaction. ReaderKey class implements the Comparable interface, so they can be sorted in an customized order.
1 | public class RecordIdentifier implements WritableComparable<RecordIdentifier> { |
Then, the ReaderKey and the file handler will be put into a TreeMap, so every time we poll for the first entry, we can get the desired file handler and read data.
1 | public class OrcRawRecordMerger { |
Select Files
Previously we pointed out that different transaction files may co-exist at the same time, so Hive needs to first select the files that are valid for the latest transaction. For instance, the following directory structure is the result of these operations: two inserts, one minor compact, one major compact, and one delete.
1 | delta_0000001_0000001_0000 |
Filtering process:
- Consult the Hive Metastore to find out the valid write ID list.
- Extract transaction information from files names, including file type, write ID range, and statement ID.
- Select the
basefile with the maximum valid write ID. - Sort
deltaanddeletefiles by write ID range:- Smaller
minWIDorders first; - If
minWIDis the same, largermaxWIDorders first; - Otherwise, sort by
stmtID; files w/ostmtIDorders first.
- Smaller
- Use the
basefile’s write ID as the current write ID, then iterate and filterdeltafiles:- If
maxWIDis larger than the current write ID, keep it, and update the current write ID; - If write ID range is the same as previous, keep the file, too.
- If
There are some special cases in this process, e.g. no base file, multiple statements, contains original data files, even ACID version 1 files. More details can be found in AcidUtils#getAcidState.
Parallel Execution
When executing in parallel environment, such as multiple Hadoop mappers, delta files need to be re-organized. In short, base and delta files can be divided into different splits, while all delete files have to be available to all splits. This ensures deleted records will not be emitted.
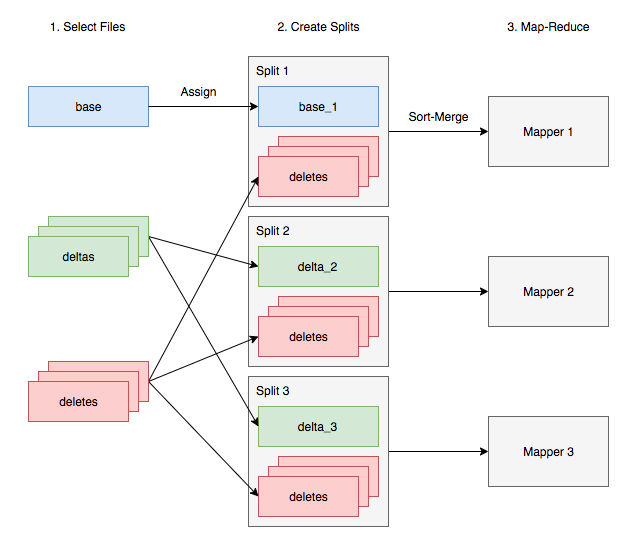
Vectorized Query
For vectoried query, Hive will first try to load all delete files into memory and construct an optimized data structure that can be used to filter out deleted rows when processing row batches. If the delete files are too large, it falls back to sort-merge algorithm.
1 | public class VectorizedOrcAcidRowBatchReader { |
Transaction Management
Hive introduced a new lock manager to support transactional tables. DbTxnManager will detect the ACID operations in query plan and contact the Hive Metastore to open and commit new transactions. It also implements the read-write lock mechanism to support normal locking requirements.
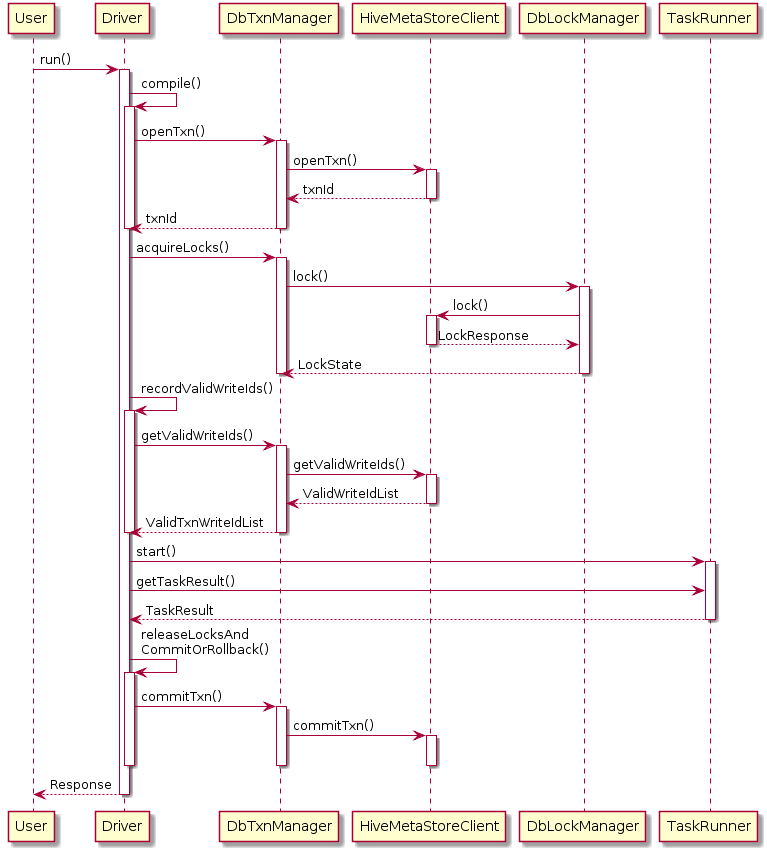
The Hive Metastore is responsible for allocating new transaction IDs. This is done in a database transaction so that multiple Metastore instances will not conflict with each other.
1 | abstract class TxnHandler { |