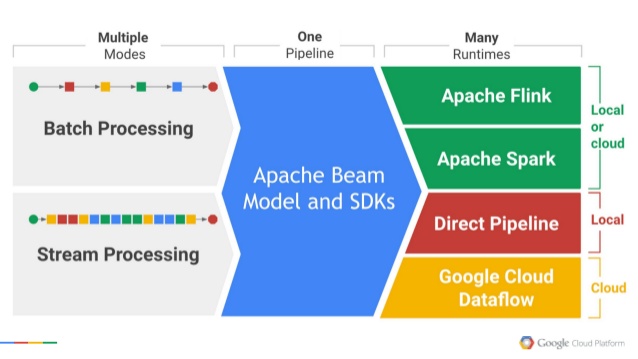
Apache Beam is a big data processing standard created by Google in 2016. It provides unified DSL to process both batch and stream data, and can be executed on popular platforms like Spark, Flink, and of course Google’s commercial product Dataflow. Beam’s model is based on previous works known as FlumeJava and Millwheel, and addresses solutions for data processing tasks like ETL, analysis, and stream processing. Currently it provides SDK in two languages, Java and Python. This article will introduce how to use Python to write Beam applications.
Installation
Apache Beam Python SDK requires Python 2.7.x. You can use pyenv to manage different Python versions, or compile from source (make sure you have SSL installed). And then you can install Beam SDK from PyPI, better in a virtual environment:
1 | $ virtualenv venv --distribute |
Wordcount Example
Wordcount is the de-facto “Hello World” in big data field, so let’s take a look at how it’s done with Beam:
1 | from __future__ import print_function |
Run the script, you’ll get the counts of difference words:
1 | (venv) $ python wordcount.py |
There’re three fundamental concepts in Apache Beam, namely Pipeline, PCollection, and Transform.
- Pipeline holds the DAG (Directed Acyclic Graph) of data and process tasks. It’s analogous to MapReduce
Joband StormTopology. - PCollection is the data structure to which we apply various operations, like parse, convert, or aggregate. You can think of it as Spark
RDD. - And Transform is where your main logic goes. Each transform will take a PCollection in and produce a new PCollection. Beam provides many built-in Transforms, and we’ll cover them later.
As in this example, Pipeline and PipelineOptions are used to construct a pipeline. Use the with statement so that context manager will invoke Pipeline.run and wait_until_finish automatically.
1 | [Output PCollection] = [Input PCollection] | [Label] >> [Transform] |
| is the operator to apply transforms, and each transform can be optionally supplied with a unique label. Transforms can be chained, and we can compose arbitrary shapes of transforms, and at runtime they’ll be represented as DAG.
beam.Create is a transform that creates PCollection from memory data, mainly for testing. Beam has built-in sources and sinks to read and write bounded or unbounded data, and it’s possible to implement our own.
beam.Map is a one-to-one transform, and in this example we convert a word string to a (word, 1) tuple. beam.FlatMap is a combination of Map and Flatten, i.e. we split each line into an array of words, and then flatten these sequences into a single one.
CombinePerKey works on two-element tuples. It groups the tuples by the first element (the key), and apply the provided function to the list of second elements (values). Finally, we use beam.ParDo to print out the counts. This is a rather basic transform, and we’ll discuss it in the following section.
Input and Output
Currently, Beam’s Python SDK has very limited supports for IO. This table (source) gives an overview of the available built-in transforms:
| Language | File-based | Messaging | Database |
|---|---|---|---|
| Java | HDFS TextIO XML |
AMQP Kafka JMS |
Hive Solr JDBC |
| Python | textio avroio tfrecordio |
- | Google Big Query Google Cloud Datastore |
The following snippet demonstrates the usage of textio:
1 | lines = p | 'Read' >> beam.io.ReadFromText('/path/to/input-*.csv') |
textio is able to read multiple input files by using wildcard or you can flatten PCollections created from difference sources. The outputs are also split into several files due to pipeline’s parallel processing nature.
Transforms
There’re basic transforms and higher-level built-ins. In general, we prefer to use the later so that we can focus on the application logic. The following table lists some commonly used higher-level transforms:
| Transform | Meaning |
|---|---|
| Create(value) | Creates a PCollection from an iterable. |
| Filter(fn) | Use callable fn to filter out elements. |
| Map(fn) | Use callable fn to do a one-to-one transformation. |
| FlatMap(fn) | Similar to Map, but fn needs to return an iterable of zero or more elements, and these iterables will be flattened into one PCollection. |
| Flatten() | Merge several PCollections into a single one. |
| Partition(fn) | Split a PCollection into several partitions. fn is a PartitionFn or a callable that accepts two arguments - element, num_partitions. |
| GroupByKey() | Works on a PCollection of key/value pairs (two-element tuples), groups by common key, and returns (key, iter<value>) pairs. |
| CoGroupByKey() | Groups results across several PCollections by key. e.g. input (k, v) and (k, w), output (k, (iter<v>, iter<w>)). |
| RemoveDuplicates() | Get distint values in PCollection. |
| CombinePerKey(fn) | Similar to GroupByKey, but combines the values by a CombineFn or a callable that takes an iterable, such as sum, max. |
| CombineGlobally(fn) | Reduces a PCollection to a single value by applying fn. |
Callable, DoFn, and ParDo
Most transforms accepts a callable as argument. In Python, callable can be a function, method, lambda expression, or class instance that has __call__ method. Under the hood, Beam will wrap the callable as a DoFn, and all these transforms will invoke ParDo, the lower-level transform, with the DoFn.
Let’s replace the expression lambda x: x.split(' ') with a DoFn class:
1 | class SplitFn(beam.DoFn): |
The ParDo transform works like FlatMap, except that it only accepts DoFn. In addition to return, we can yield element from process method:
1 | class SplitAndPairWithOneFn(beam.DoFn): |
Combiner Functions
Combiner functions, or CombineFn, are used to reduce a collection of elements into a single value. You can either perform on the entire PCollection (CombineGlobally), or combine the values for each key (CombinePerKey). Beam is capable of wrapping callables into CombinFn. The callable should take an iterable and returns a single value. Since Beam distributes computation to multiple nodes, the combiner function will be invoked multiple times to get partial results, so they ought to be commutative and associative. sum, min, max are good examples.
Beam provides some built-in combiners like count, mean, top. Take count for instance, the following two lines are equivalent, they return the total count of lines.
1 | lines | beam.combiners.Count.Globally() |
Other combiners can be found in Beam Python SDK Documentation (link). For more complex combiners, we need to subclass the CombinFn and implement four methods. Take the built-in Mean for an example:
apache_beam/transforms/combiners.py
1 | class MeanCombineFn(core.CombineFn): |
Composite Transform
Take a look at the source code of beam.combiners.Count.Globally we used before. It subclasses PTransform and applies some transforms to the PCollection. This forms a sub-graph of DAG, and we call it composite transform. Composite transforms are used to gather relative codes into logical modules, making them easy to understand and maintain.
1 | class Count(object): |
More built-in transforms are listed below:
| Transform | Meaning |
|---|---|
| Count.Globally() | Count the total number of elements. |
| Count.PerKey() | Count number elements of each unique key. |
| Count.PerElement() | Count the occurrences of each element. |
| Mean.Globally() | Compute the average of all elements. |
| Mean.PerKey() | Compute the averages for each key. |
| Top.Of(n, reverse) | Get the top n elements from the PCollection. See also Top.Largest(n), Top.Smallest(n). |
| Top.PerKey(n, reverse) | Get top n elements for each key. See also Top.LargestPerKey(n), Top.SmallestPerKey(n) |
| Sample.FixedSizeGlobally(n) | Get a sample of n elements. |
| Sample.FixedSizePerKey(n) | Get samples from each key. |
| ToList() | Combine to a single list. |
| ToDict() | Combine to a single dict. Works on 2-element tuples. |
Windowing
When processing event data, such as access log or click stream, there’s an event time property attached to every item, and it’s common to perform aggregation on a per-time-window basis. With Beam, we can define different kinds of windows to divide event data into groups. Windowing can be used in both bounded and unbounded data source. Since current Python SDK only supports bounded source, the following example will work on an offline access log file, but the process can be applied to unbounded source as is.
1 | 64.242.88.10 - - [07/Mar/2004:16:05:49 -0800] "GET /edit HTTP/1.1" 401 12846 |
logmining.py, full source code can be found on GitHub (link).
1 | lines = p | 'Create' >> beam.io.ReadFromText('access.log') |
First of all, we need to add a timestamp to each record. extract_timestamp is a custom function to parse [07/Mar/2004:16:05:49 -0800] as a unix timestamp. TimestampedValue links this timestamp to the record. Then we define a sliding window with the size 10 minutes and period 5 minutes, which means the first window is [00:00, 00:10), second window is [00:05, 00:15), and so forth. All windows have a 10 minutes duration, and adjacent windows have a 5 minutes shift. Sliding window is different from fixed window, in that the same elements could appear in different windows. The combiner function is a simple count, so the pipeline result of the first five logs will be:
1 | [2004-03-08T00:00:00Z, 2004-03-08T00:10:00Z) @ 2 |
In stream processing for unbounded source, event data will arrive in different order, so we need to deal with late data with Beam’s watermark and trigger facility. This is a rather advanced topic, and the Python SDK has not yet implemented this feature. If you’re interested, please refer to Stream 101 and 102 articles.
Pipeline Runner
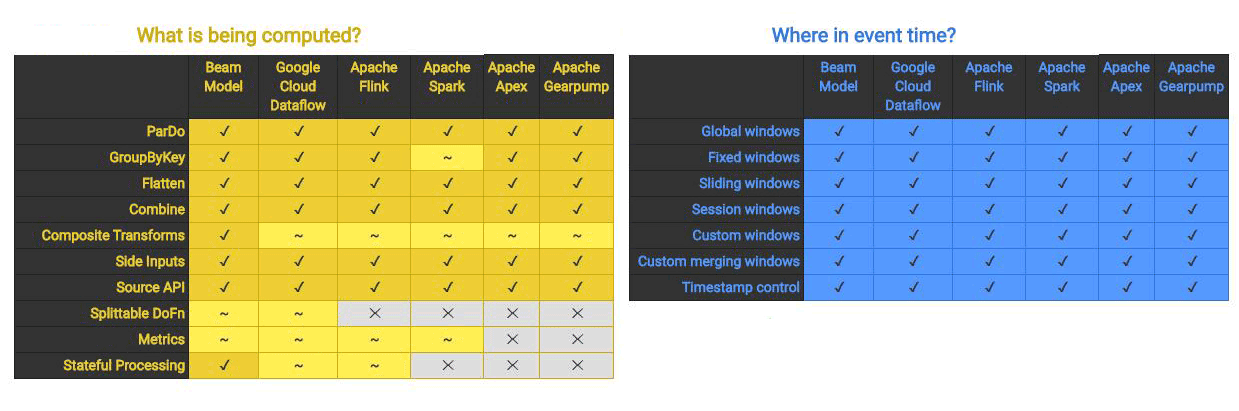
As mentioned above, Apache Beam is just a standard that provides SDK and APIs. It’s the pipeline runner that is responsible to execute the workflow graph. The following matrix lists all available runners and their capabilities compared to Beam Model.