In the paper Tidy Data, Dr. Wickham proposed a specific form of data structure: each variable is a column, each observation is a row, and each type of observational unit is a table. He argued that with tidy data, data analysts can manipulate, model, and visualize data more easily and effectively. He lists five common data structures that are untidy, and demonstrates how to use R language to tidy them. In this article, we’ll use Python and Pandas to achieve the same tidiness.
Source code and demo data can be found on GitHub (link), and readers are supposed to have Python environment installed, preferably with Anaconda and Spyder IDE.
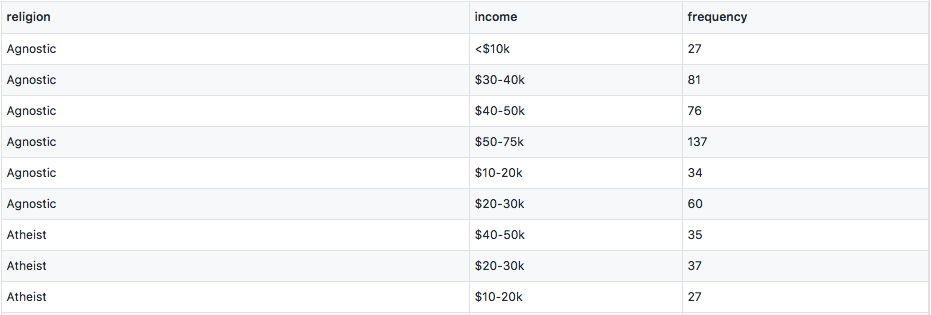
Column headers are values, not variable names
1 | import pandas as pd |
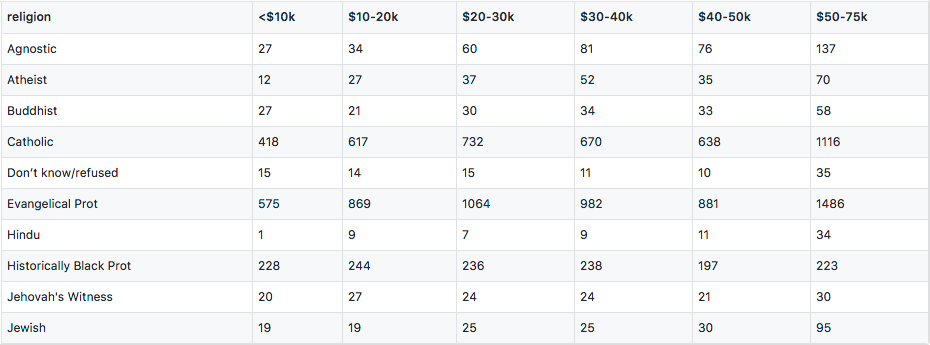
Column names “<$10k”, “$10-20k” are really income ranges that constitutes a variable. Variables are measurements of attributes, like height, weight, and in this case, income and religion. The values within the table form another variable, frequency. To make each variable a column, we do the following transformation:
1 | df = df.set_index('religion') |